Per identificare il primo illecito si può operare solo osservando il processo di stesura della tesi: per es. se uno studente propone al relatore l’argomento della tesi, poi non si fa più vivo, infine, dopo qualche tempo, presenta il prodotto finale, informato, ben strutturato, scritto bene, allora o è un genio o è un furfante. Non mancano i casi di genialità, ma sono più diffusi i casi di furfanteria e un relatore di tesi dovrebbe essere in grado di accorgersene.
Per identificare il secondo illecito, si può lavorare sul prodotto. Se ci sono stridenti mutamenti di stile tra una parte e l’altra, se ci sono ripetizioni tra un capitolo e l’altro, se ci sono vistose contraddizioni tra una sezione e l’altra, al relatore dovrebbe sorgere il sospetto che si tratti di un collage di fonti diverse, ricopiate senza attenzione. Ma se il plagio è fatto bene, per es. ricopiando una sola fonte, scritta con uno stile non troppo ricercato o personale, può essere difficile anche per un lettore esperto, quale dovrebbe essere il relatore, scoprire l’inganno.
Per questo, un numero sempre maggiore di Università fornisce a studenti e docenti strumenti informatici per l’individuazione dei plagi. Sono strumenti utilissimi, fondati su metodi statistico-matematici di analisi della similarità dei testi. Si basano sugli stessi sistemi che permettono di dare una base quantitativa alle valutazioni qualitative
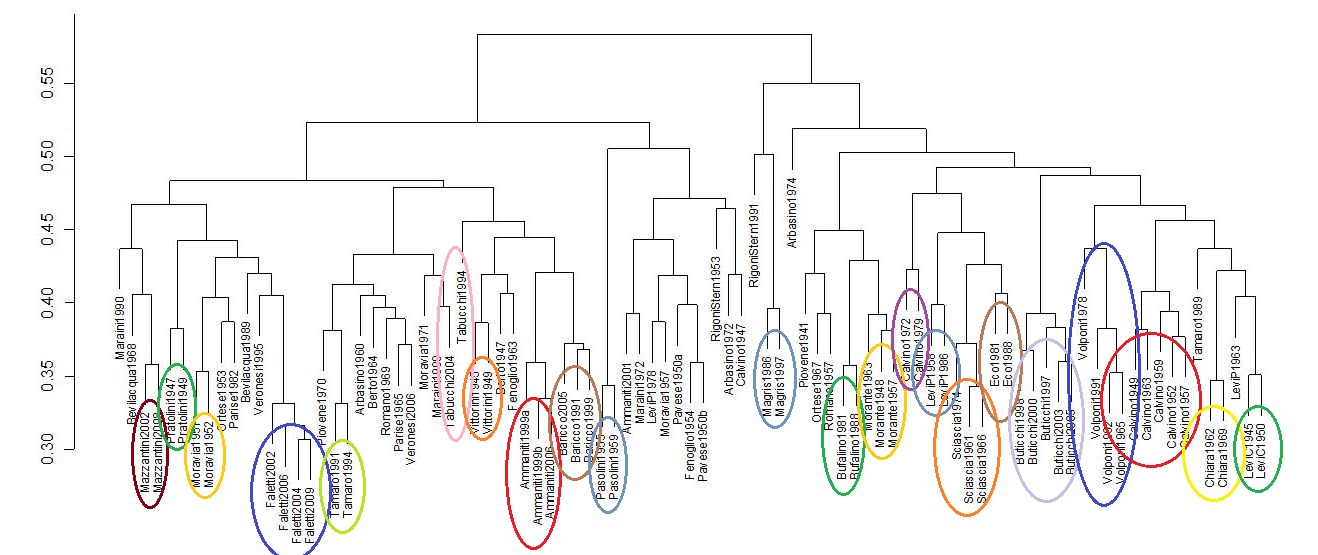
La capacità di individuare le somiglianze stilistiche, con sistemi quantitativi e quindi con uno sguardo ai testi nel loro complesso, non è completa, ma è piuttosto alta. Per esempio, una prova fatta su 92 opere di 33 scrittori italiani contemporanei, ciascuno dei quali contribuisce con almeno due opere, ha fatto vedere che le opere dello stesso autore vengono correttamente abbinate tra di loro in un numero considerevole di casi:
{kind=link}
Il compito di un software antiplagio è, però, molto più semplice delle ricerche sull’attribuzione d’autore. Non si tratta, infatti, di risalire alla paternità effettiva dei testi analizzati. Si tratta, più semplicemente, di verificare quanta parte di un testo coincide, per segmenti di una certa ampiezza (per es. per sequenze di tre, o quattro, o cinque parole, oppure per sequenze di un certo numero di caratteri), con parte di testi presenti in un corpus di riferimento. La bontà di un software si gioca, prima ancora che sulla formula usata per verificare la sovrapposizione tra testi, sull’ampiezza del corpus di riferimento e sulla velocità con cui si riesce a effettuare il confronto. Do per scontato, anche se non l’ho potuto verificare (le ditte produttrici sono molto riservate, per non dire reticenti, nello svelare i loro metodi e le loro risorse), che i software più utilizzati per questi scopi (Trinitin e Compilatio) utilizzino formule di accertata efficacia, abbiano raccolto un’ampia base di raffronto composta da un vasto insieme di testi diffusi su web, dispongano di un numero di server in grado di dare risposte rapide a un gran numero di richieste di verifica (come è facilmente comprensibile, le tesi vengano terminate più o meno nello stesso periodo e i server sui quali girano i software antiplagio devono essere in grado di sostenere picchi di grande intensità).
Devo però dire che sono piuttosto insoddisfatto del modo in cui molte università e, soprattutto, le ditte produttrici dei software antiplagio affrontano il problema, dimenticando che non si tratta di istituire un’operazione di polizia che va a caccia di plagi (e per di più di plagi in un settore particolare, quello della ricerca), ma di avviare un’attività formativa che, prima di tutto, faccia capire agli studenti cosa
Le mie perplessità si basano su ragioni teoriche, metodologiche, formative, economiche.
Dal punto di vista teorico, bisognerebbe per prima cosa accordarsi su quale sia il tasso di similarità con altri testi accettabile in una tesi di laurea. Ogni testo scientifico non può che far riferimento agli studi che l’hanno preceduto, citandoli testualmente o sintetizzandone, a volte con espressioni simili, il contenuto. Nelle linee guida per la scrittura accademica in inglese è facile incontrare indicazioni come la seguente: «In papers that rely on secondary research, this section would provide the necessary background or history for understanding the discussion to come. A Review of Literature more specifically synthesizes information from a variety of significant sources related to the major point of the paper».
Un certo tasso di similitudine con testi già esistenti non è, quindi, un limite di una tesi di laurea, bensì un pregio: vuol dire che lo studente usa una strategia testuale adeguata alla scrittura accademica. Non parliamo poi delle tesi dei settori letterari e linguistici, nei quali la citazione dei testi analizzati è un obbligo metodologico, o di quelle di argomento giuridico, nelle quali la citazione della giurisprudenza corrente è altrettanto d’obbligo.
E con questo arriviamo alla terza categoria di perplessità, quelle didattiche. Se non mi è sfuggita qualche informazione, le Università che utilizzano i correnti sistemi antiplagio obbligano gli studenti a usare un software di cui non si sa nulla, confidando acriticamente e
{kind=link}
Infine vanno prese in esame le questioni economiche, e comunque il rapporto costi-benefici. Pare che questi software costino alle università veramente poco (ma alcune ditte fanno pagare agli studenti servizi poco più che basilari). Comunque, dalla stampa apprendo che a Venezia, in occasione della prima applicazione del software (sessione estiva 2011), su 300 tesi di laurea magistrale analizzate, ne sono state individuate 2 che contenevano similarità da web superiori all’80%. Pur considerando il valore deterrente dell’utilizzo del software, la scoperta di 2 plagi su 300 tesi (0,6%) è pochino. Dati un po’ più rilevanti provengono da Bologna, dove le tesi collocate nelle fasce più alte di similitudine oscillano dal 5% del 2011 al 3,7% del 2014. Ci si può chiedere se valga la pena di appesantire la trafila per consegnare la tesi, se poi il numero di plagi scoperti è nettamente inferiore al numero dei plagi di cui un bravo professore si accorge strada facendo, basandosi sulla sua competenza, sul suo fiuto e sulla sua interazione con lo studente.
Nel valutare il rapporto costi-benefici, occorre anche tenere conto di cosa un software di analisi testuale non può individuare: i sotftware non riescono a scoprire il plagio di algoritmi, formule, diagrammi, in quanto essi non si presentano come sequenze testuali, e come tali sfuggono al controllo del software e il plagio da lavori in una
La conclusione di tutto questo è che sbagliano le università che si avvalgono di software di individuazione automatica delle similarità dei testi? Certamente no. Le conclusioni del mio ragionamento sono altre:
da una parte, sottolineare che le università, come già fanno molte di esse, devono utilizzare questi software prima che come rilevatori di illeciti (a basso rapporto costi-benefici), come strumento per sensibilizzare gli studenti sull’etica del lavoro scientifico e sui modi corretti di riferirsi al lavoro altrui (in un’epoca di generalizzato taglia-e-incolla e di ampia disponibilità pubblica di contenuti, sia pure di valore diverso, in Internet, si è persa la sensibilità per la tutela della proprietà intellettuale). Se l’utilizzo dei software antiplagio deve avere primariamente una finalità formativa, ne consegue che è fondamentale l’esclusione di ogni approccio acritico e disinformato sulle metodologie adottate e di qualsiasi atteggiamento fideistico nei confronti di questi strumenti, che non hanno capacità miracolistiche (le Università non possono imitare le irrealistiche attività dei finti laboratori di scienza forense oggetto di diverse serie di telefilm americani); dall’altra suggerire che siano le stesse Università, o almeno le più attrezzate tra di esse, a prendere in mano, come oggetto di ricerca e di successiva applicazione, l’ideazione e la messa in opera di strumenti di individuazione del plagio, nei quali le questioni metodologiche, deontologiche e formative prevalgano sulle esigenze industriali e commerciali delle aziende private.
Vedi anche Scrivere, copiare, comperare una tesi di laurea